

As it becomes easier for individuals and organizations to amass large numbers of documents, a new opportunity presents itself. What if you aren’t looking for a single needle in a haystack? What if you wanted to leverage the vast number of existing documents on a subject to help you better understand the subject? One needs an understanding of the totality of the collection. What topics are represented, and how do you create a meaningful overview for troves of documents? To answer these sorts of questions, an approach other than search is needed. At Fathom, we’ve spent the past few years exploring this approach to large document sets. Laniakea is the culmination of much of that work.
With Laniakea, we have mapped out the areas of interest in a set of documents. We combined our design approach with natural language processing techniques to create a general overview of a document set. You can browse documents or drill in to see how subtopics break into categories of their own.
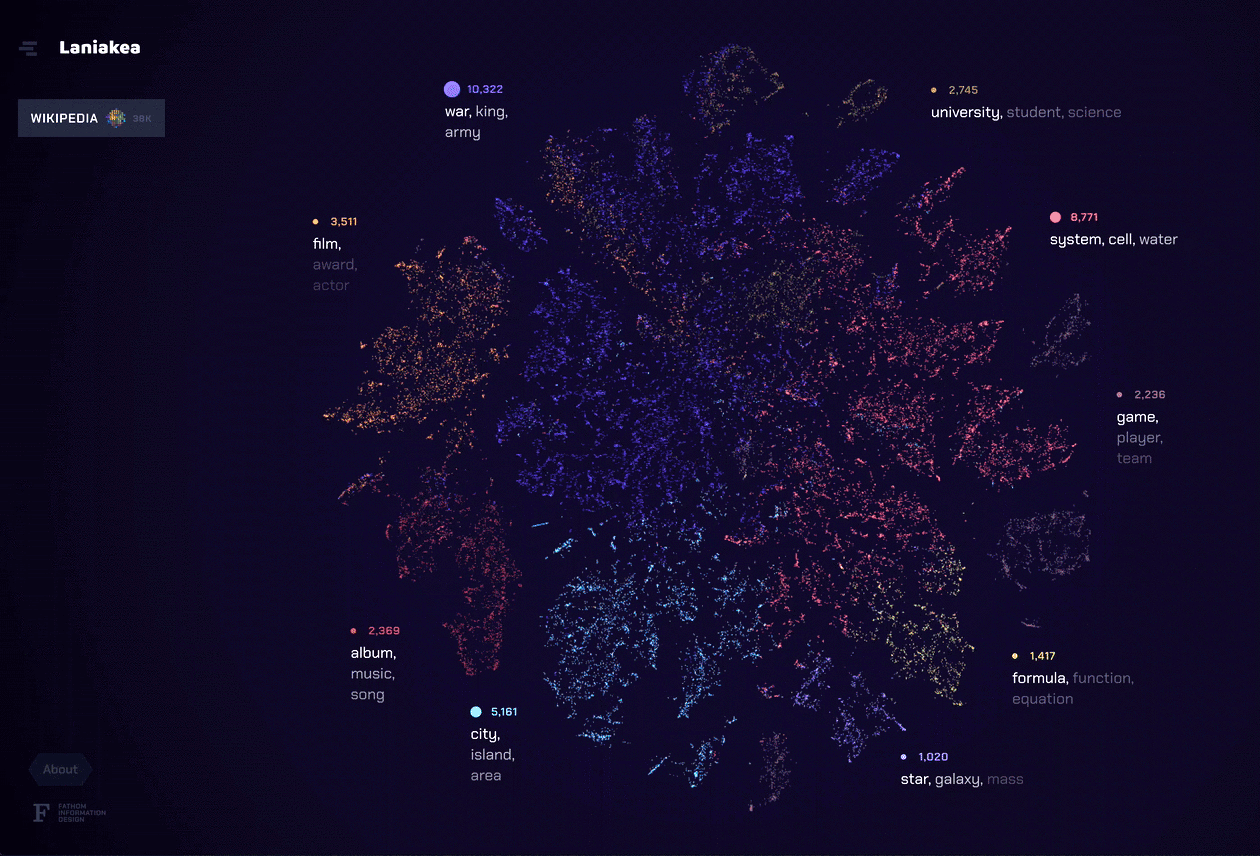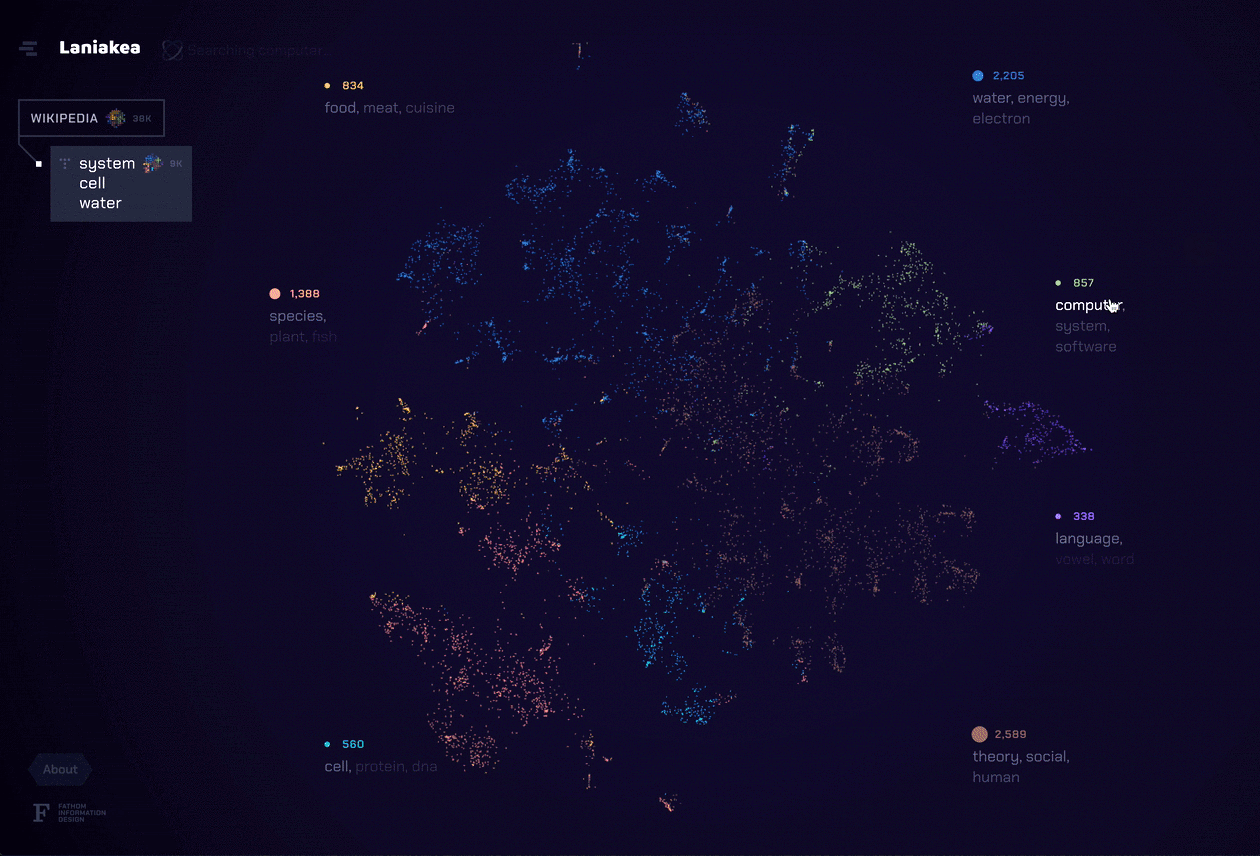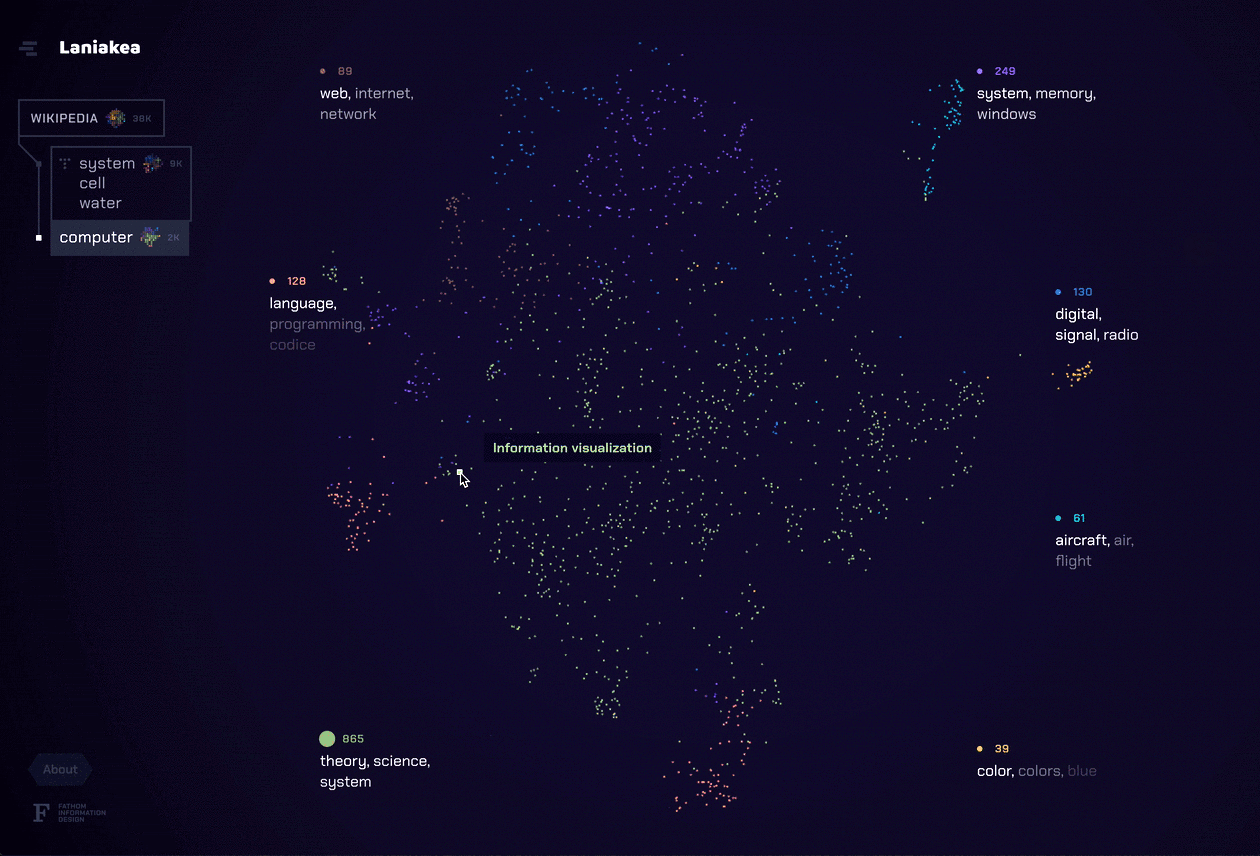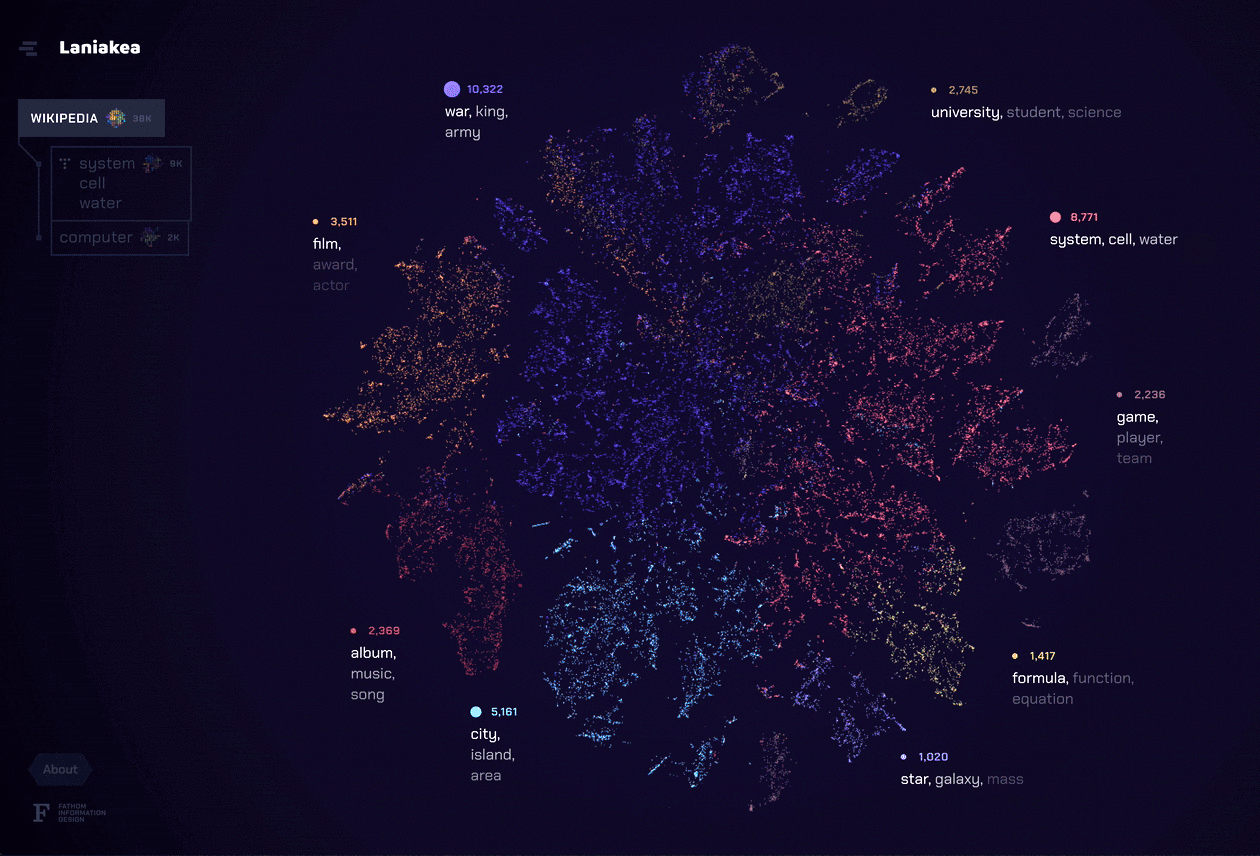
In the app, each dot represents a document, and clusters of documents indicate that they share a common theme. Around the outside edge we list the dominant topics for documents on display. Hovering a topic–or one of its top terms–reveals the documents associated with it. Similarly, clicking a topic or term reveals how its component documents assemble into new categories.
We released a few versions of Laniakea to demonstrate how it applies to different document sets. The Wikipedia set frames the articles that the Wikipedia Project deems vital. The PubMed set models 100,000 documents sampled from the National Institutes of Health repository of medical and biological research. And for Halloween, we modeled all the articles in Wikipedia that have the word “ghost”.
We are excited to share Laniakea, and hope you enjoy it.
We’d love to hear what you’re working on, what you’re curious about, and what messy data problems we can help you solve. Drop us a line at hello@fathom.info, or you can subscribe to our newsletter for updates.