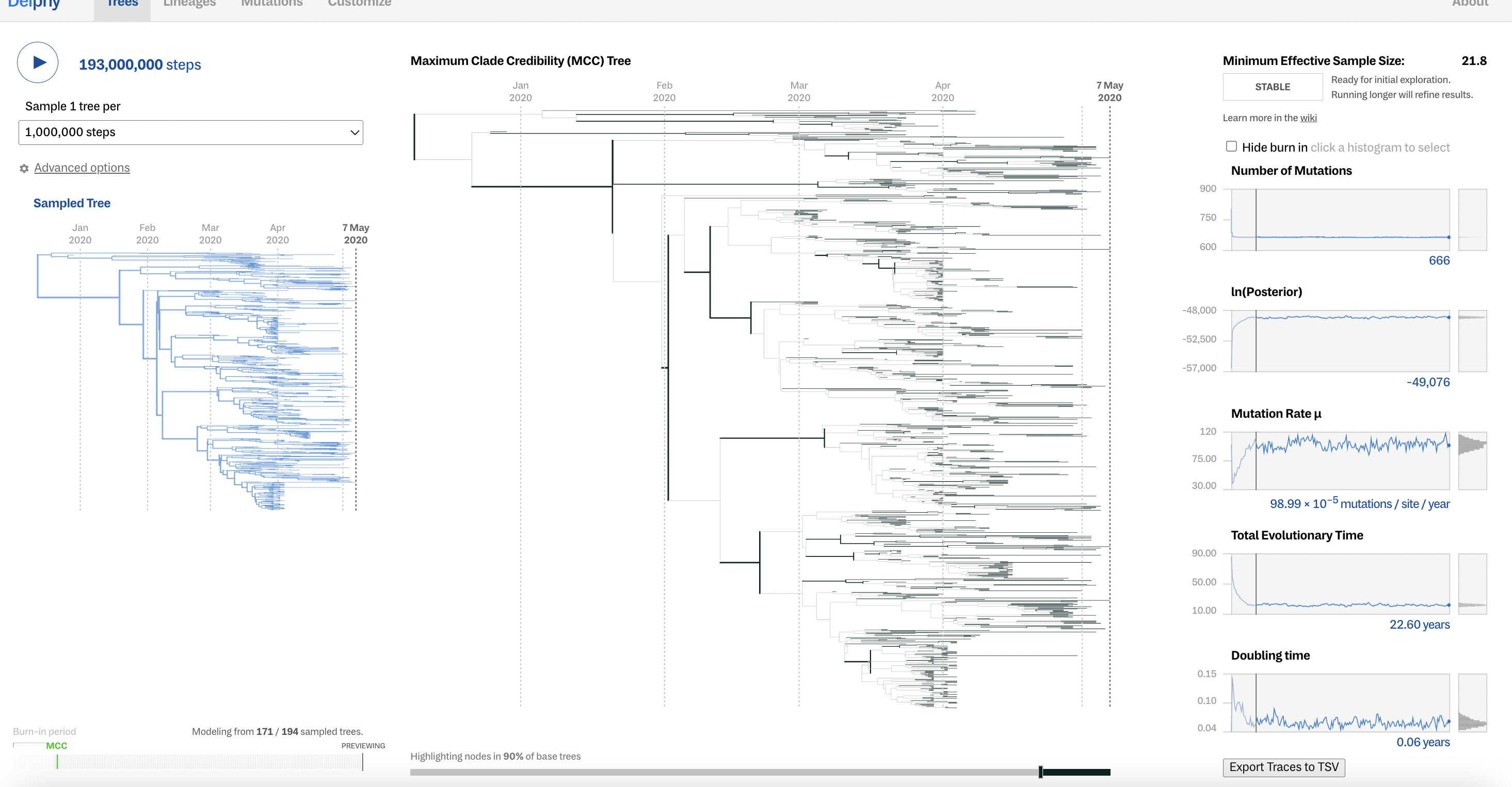
Delphy is an incredibly fast tool we built with the Broad Institute to make phylogenetic trees (you can read more about it here). One aspect of it that we are super proud of is its potential to democratize phylogenetics. Most other tools require some programming expertise in order to get them to run, and they work best on powerful servers. To run Delphy, you merely need to go to the web page and open your file. Once you hit the run button, the tree jumps around for a bit until it stabilizes into a useful interpretation of your data. This ease of use opens up phylogenetics to a whole new audience.
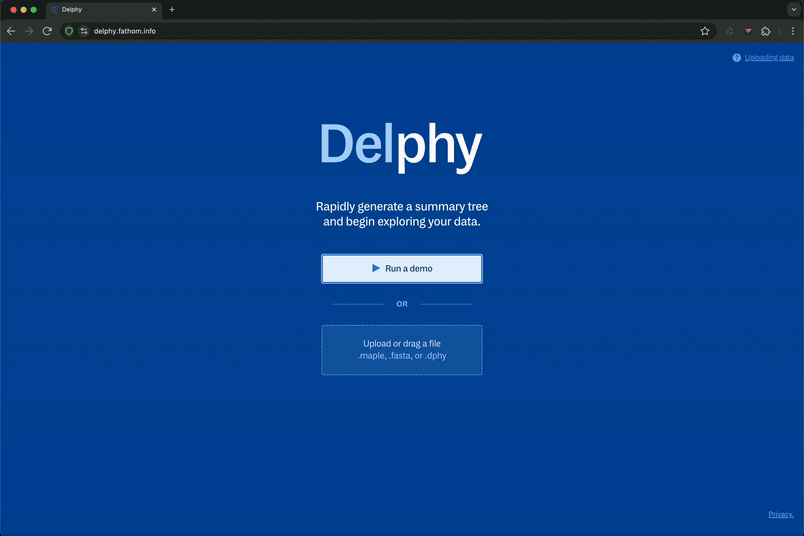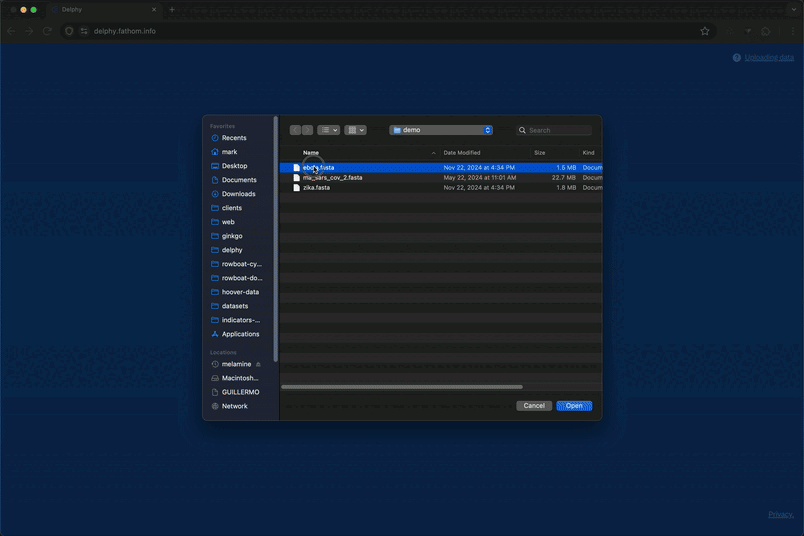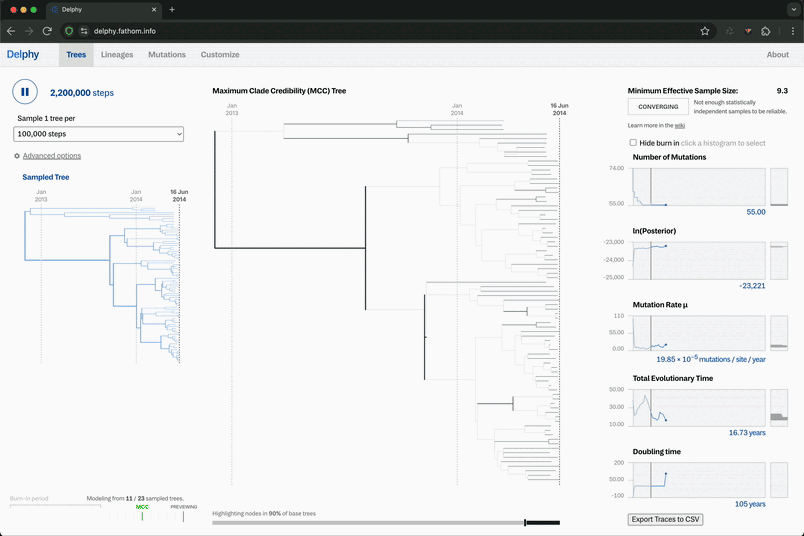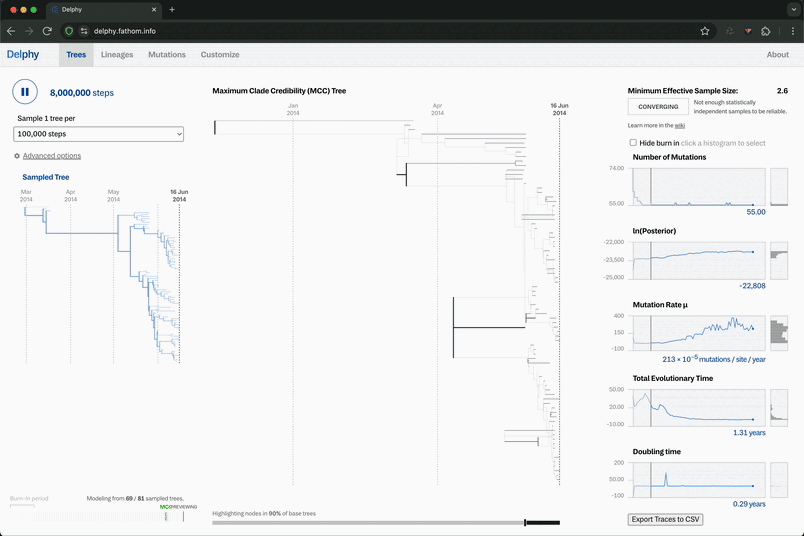
And we’ve had the good fortune to get feedback from some of those new users. They are excited to quickly make trees without installing any software and without uploading data to remote servers. But! We also realized that there were a couple things flying under their radar. The phylogenetic algorithms behind Delphy require users to make certain judgement calls, and they didn’t realize those decisions needed to be made. Those decisions focus on a basic question: how do you know when the results are stable enough to start using them?
For those experienced with other tools, the information behind those decisions is presented clearly, and the controls to set them are readily available. Even better, Delphy enables users to make those calls in real time, a feature unavailable elsewhere. All the same, that whole aspect of the application was lost on newcomers.
Thankfully, our collaborator Patrick Varilly was able to tease out good defaults for these decisions. Or, more precisely, he was able to create algorithms that allow us to find good defaults. With that new logic available, we worked with him to provide straightforward guidance for those who need it.
In the latest release of Delphy, you can see these updates. We provide a summary status of the run, so users can tell when the results are ready for exploration. And we automatically trim the samples at the start of the run that just add noise and muddy the results. You can read more about why that’s important on our wiki.
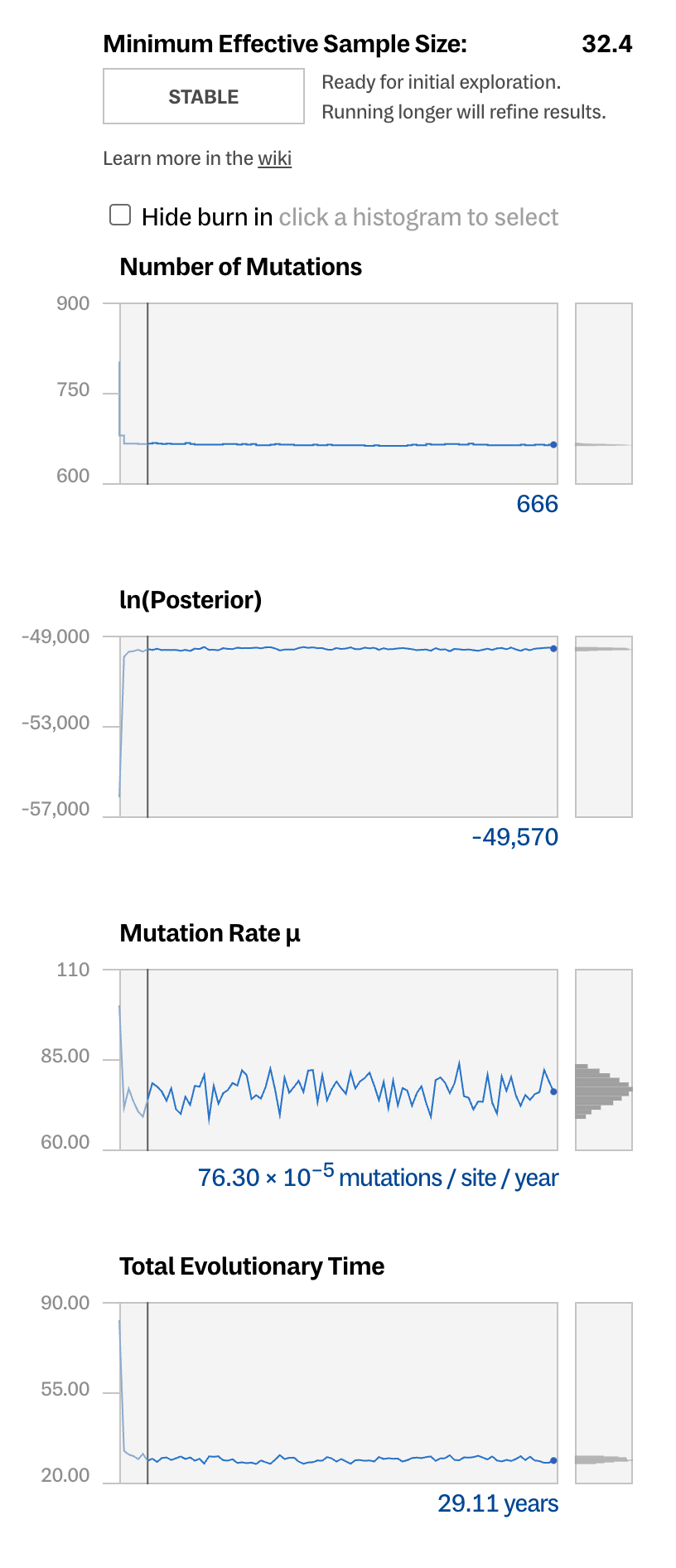
It’s exciting to help open this field up to a wider audience, and remove technical barriers for scientists around the world to perform this kind of analysis. We are actively working on Delphy, rounding out the sorts of models and analysis it supports, as well as adding clarity to different stages of processing. So check back often for updates!
We’d love to hear what you’re working on, what you’re curious about, and what messy data problems we can help you solve. Drop us a line at hello@fathom.info, or you can subscribe to our newsletter for updates.